Artificial intelligence (AI) has recently approached or even surpassed human-level performance in many applications. However, the successful deployment of AI requires sufficient robustness against adversarial attacks of all types and in all phases of the model life cycle. Although much progress has been made in enhancing the robustness of AI algorithms, there is a lack of systematic studies on hardware-oriented vulnerabilities and countermeasures, which also opens up demand for AI security education. Given this pressing need, this project aims at exploring novel hardware-oriented adversarial AI concepts and developing fundamental defensive strategies against such vulnerabilities to protect next-generation AI systems.
This project has four thrusts. In Thrust 1, this project will exploit new adversarial attacks on deep neural network systems, featuring the design of an algorithm-hardware collaborative backdoor attack. Then in Thrust 2, it will develop methodologies that incorporate the hardware aspect into defense for enhancing adversarial robustness against vulnerabilities in the untrusted semiconductor supply chain. Subsequently, in Thrust 3, this project will develop novel signature embedding frameworks to protect the integrity of deep neural network models in the untrusted model building supply chain and finally in Thrust 4, it will model recovery strategies as an innovative approach to mitigate hardware-oriented fault attacks in the untrusted user-space.
This project will yield novel methodologies for ensuring trust in AI systems from both the algorithm and hardware perspectives to meet the future needs of commercial products and national defense. In addition, it will catalyze advances in emerging AI applications across a broad range of sectors, including healthcare, autonomous vehicles, and Internet of things (IoT), triggering widespread implementation of AI in mobile and edge devices. New theories and techniques developed in this project will be integrated into undergraduate and graduate education and used to raise public awareness and promote understanding of the importance of AI security.
Deep learning is a powerful tool for combating contemporary security threats. However, the neural network models that power this technology have been demonstrated to be vulnerable in adversarial settings. Our research has explored the vulnerability of such systems and demonstrated that deep learning systems in a security application are a viable target that can compromise the system's security.
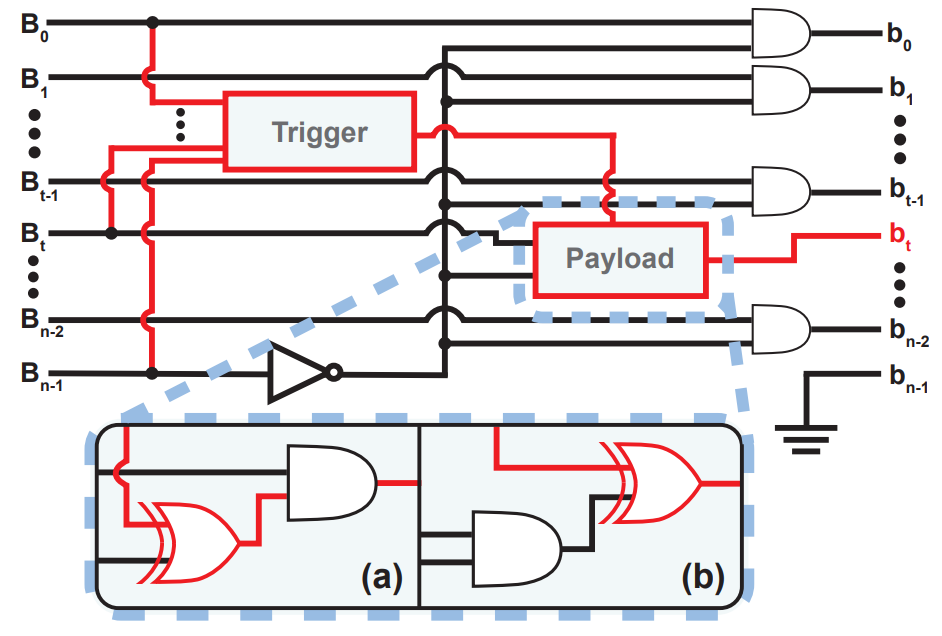
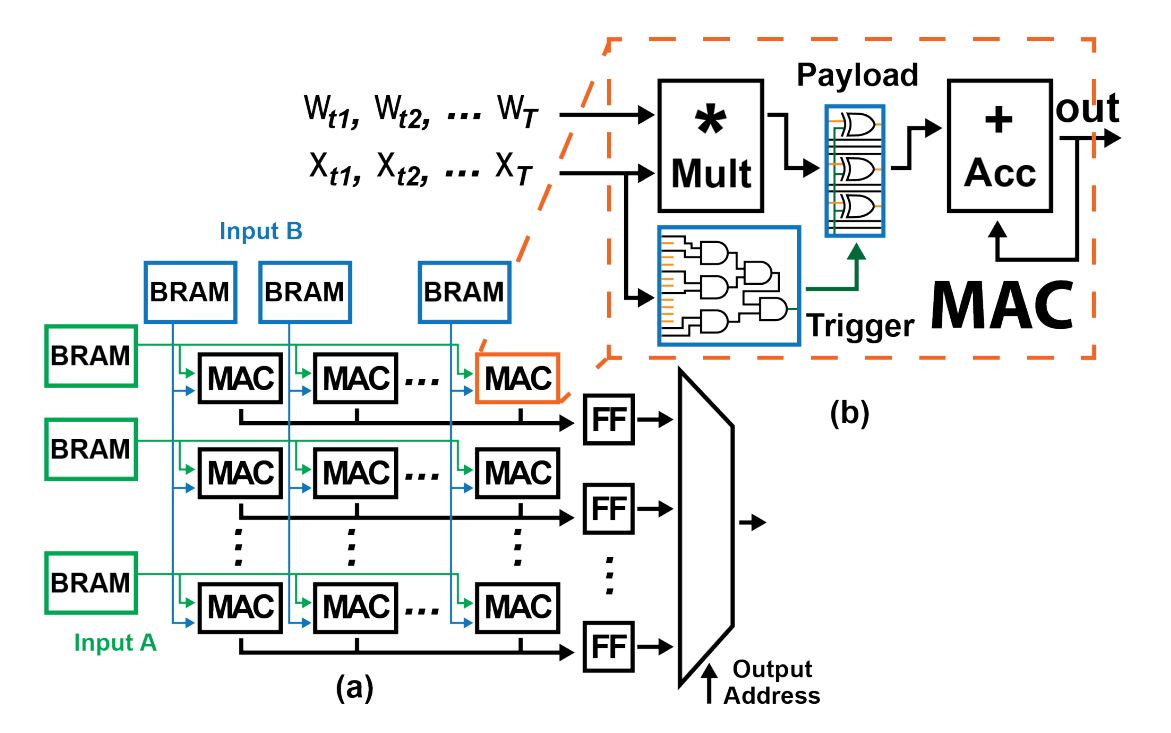
As deep learning develops further, hardware optimized to compute neural network computations will become increasingly valuable. These resources will become a target of adversaries that could embed hardware Trojans, malicious modifications into the designs of these systems. Meanwhile, adversaries can introduce backdoors into a Neural Network to control the model during inference. This is often achieved through modifications to the model's parameters that change the functionality to allow for manipulation by the adversary without affecting typical usage. To evaluate the capabilities and vulnerabilities in such settings, we developed a method for embedding hardware Trojans into a device that introduces backdoors into a deep neural network executed on it. We also developed a novel method of embedding backdoors into deep learning models by altering the function of its base mathematical operations.
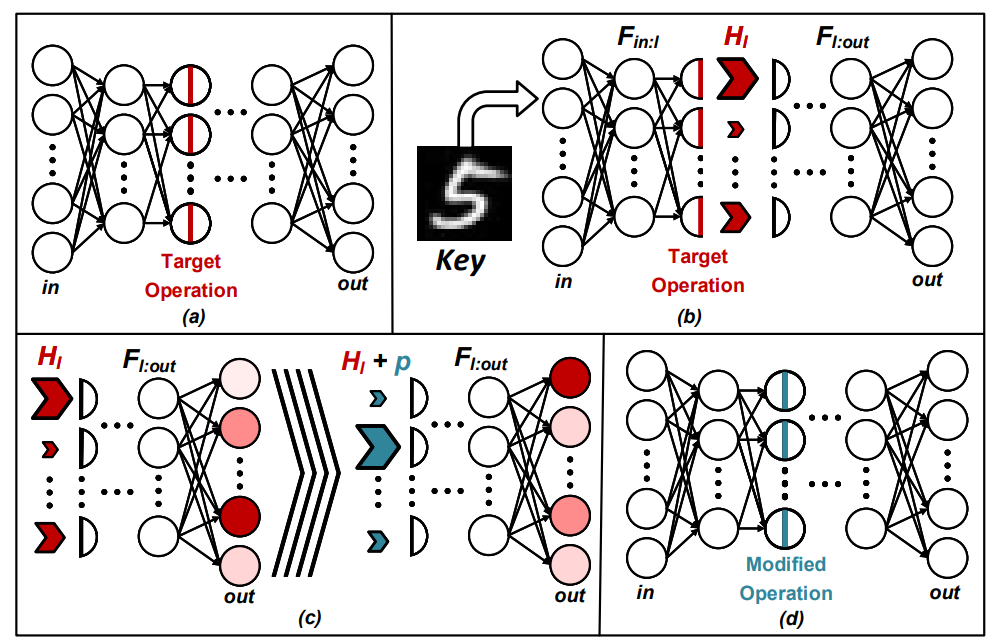
Adversaries may target well-optimized deep learning hardware for theft subverting profits from their rightful owner, and disincentivizing technological development. As such, a method of watermarking their hardware to identify if an adversary is fraudulently using their intellectual property. Our research developed an algorithm for embedding watermarks that identify deep learning hardware accelerators.
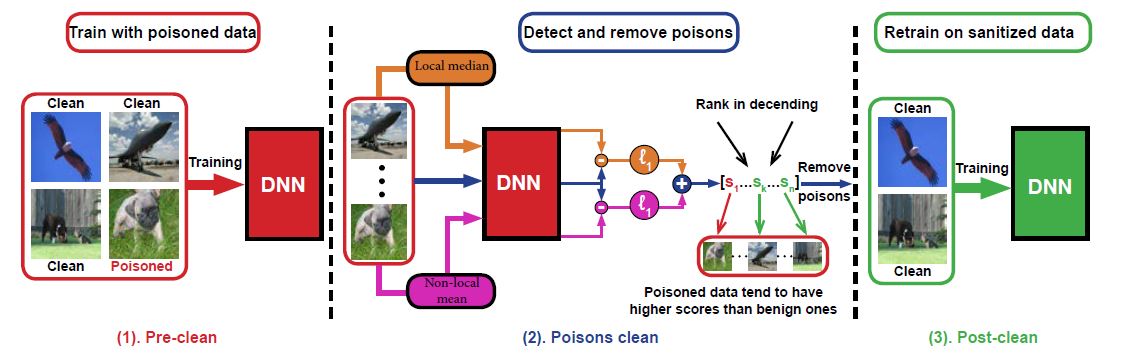
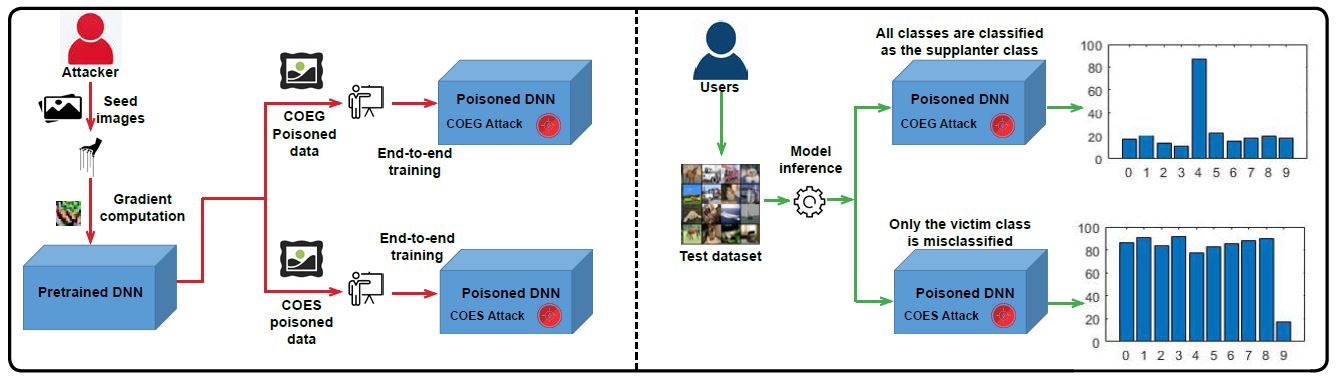
Poisoning attacks mainly aim at either the models' availability (i.e., subvert model performance) or integrity (i.e., cause misclassification on specific input instances). Our work advanced the goal of the poisoning availability attacks to a per-class basis that focused on manipulating the malicious behavior of each class. We proposed gradient-based class-oriented algorithms to achieve the adversarial goals.
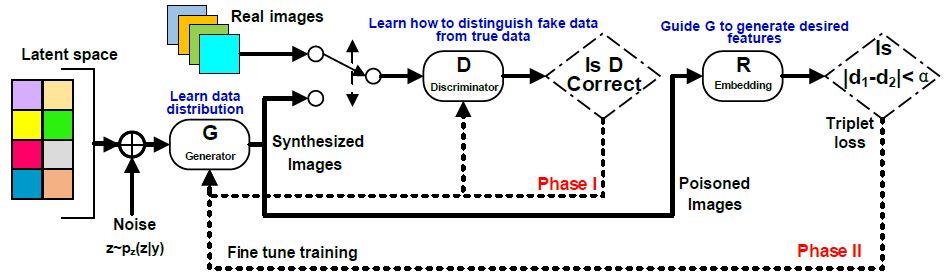
Poisoning availability attacks degrade overall model accuracy and cause a denial of service by contaminating the training dataset. However, it is challenging to generate effective and stealthy poisoned data at a large scale. We developed a framework that optimizes feature space representations of poisoned data and employs generative adversarial nets to generate high-quality clean-label poisoned data.
Data poisoning attacks are emerging threats to deep neural networks. Adversaries inject a fraction of well-crafted poisoned data in the training dataset and introduce malicious behaviors to DNNs trained on the poisoned dataset. Our research developed defensive strategies against different poisoning attacks such as availability attacks and backdoor attacks.